The audio track for this teaser video was generated with the help of Suno.
TL;DR
Cora is a new image editing method that enables flexible and accurate edits-like pose changes, object insertions, and background swaps-using only 4 diffusion steps.
Unlike other fast methods that create visual artifacts, Cora uses semantic correspondences between the original and edited image to preserve structure and appearance where needed.
It works by:
Correcting noise in a way that respects spatial changes
Interpolating attention maps between source and target with linear interpolation for smooth transition between source appearance and target text prompt for fine-grained control on appearance
Control on structure alignment with query matching for edits that maintain the layout
It's fast, controllable, and produces high-quality edits with better fidelity than existing few-step methods.
Editing demo
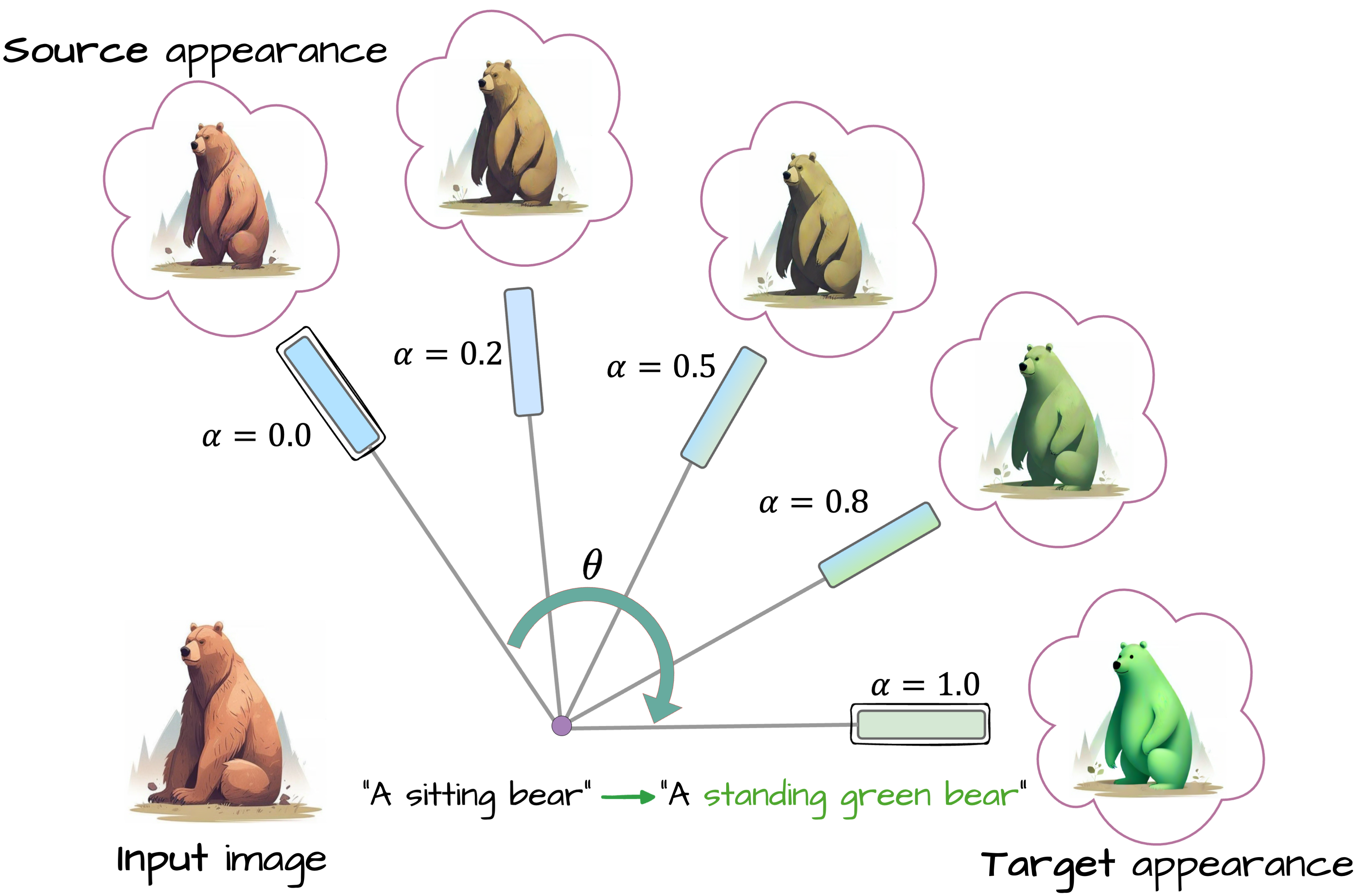
Click a thumbnail, then adjust α (Appearance alignment) and β (Structure alignment) from 0 (complete alignment with input image) to 1 (complete adherence to text prompt) to see the output.
β = 0.0
Edit prompt: "A standing green bear"
α = 0.0
Comparison with ChatGPT 4o
While the new ChatGPT 4o image-editing model can also generate high-quality outputs, our approach provides explicit user control over appearance and structural alignment with the input image-resulting in more consistent and customizable edits.
Abstract
Image editing is an important task in computer graphics, vision, and VFX, with recent diffusion-based methods achieving fast and high-quality results. However, edits requiring significant structural changes, such as non-rigid deformations, object modifications, or content generation, remain challenging. Existing few step editing approaches produce artifacts such as irrelevant texture or struggle to preserve key attributes of the source image (e.g., pose). We introduce Cora, a novel editing framework that addresses these limitations by introducing correspondence-aware noise correction and interpolated attention maps. Our method aligns textures and structures between the source and target images through semantic correspondence, enabling accurate texture transfer while generating new content when necessary. Cora offers control over the balance between content generation and preservation. Extensive experiments demonstrate that, quantitatively and qualitatively, Cora excels in maintaining structure, textures, and identity across diverse edits, including pose changes, object addition, and texture refinements. User studies confirm that Cora delivers superior results, outperforming alternatives.
Correspondence-aware latent correction (CLC)
Click a thumbnail to see the editing prompt and interactively compare with and without CLC.
Prompt will appear here
w/o CLC
w/ CLC
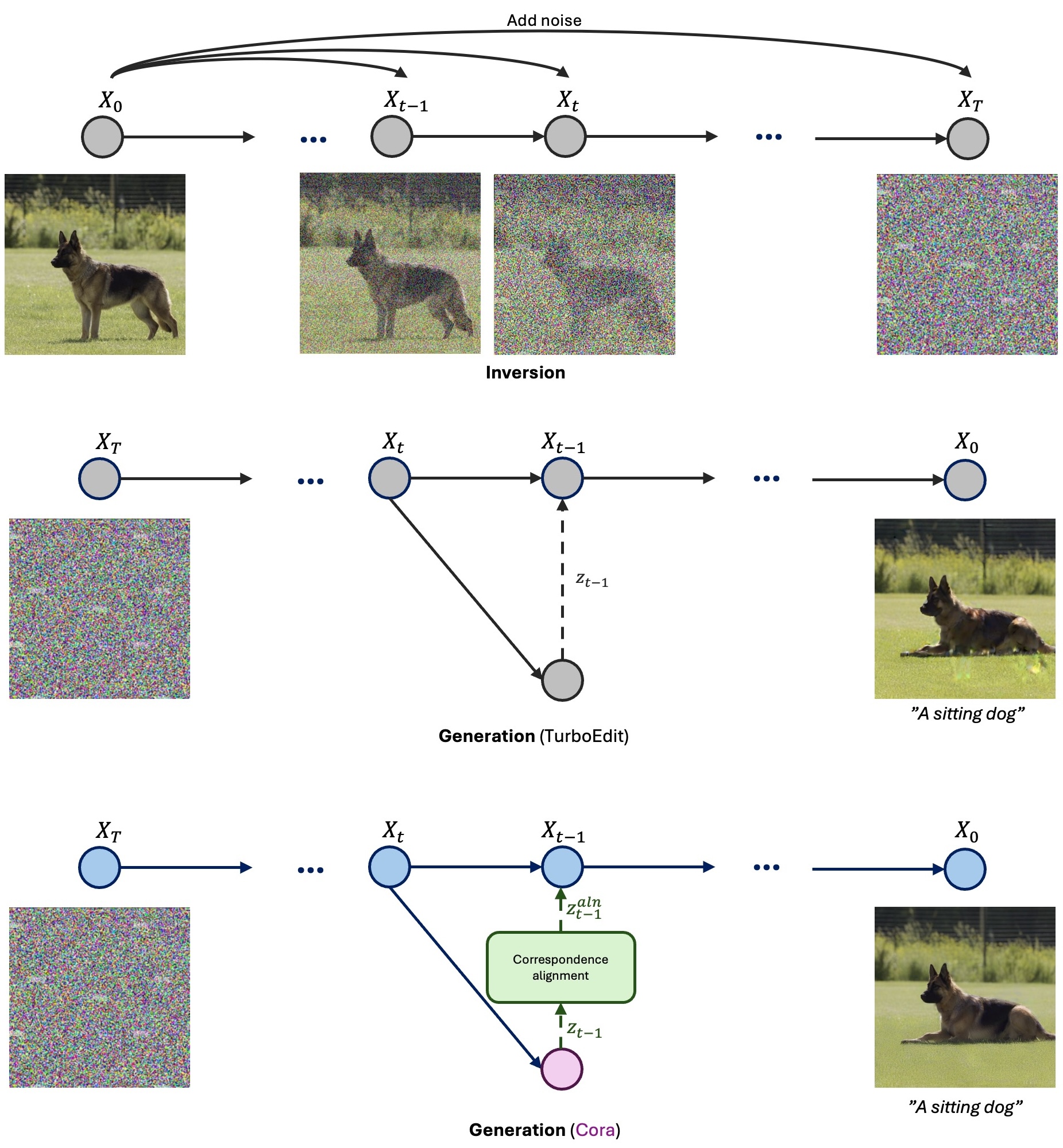
Image editing with diffusion models typically requires inversion: recovering the denoising trajectory from the input image X0 to noise XT. We build on Edit-Friendly DDPM inversion, where noise is added step-by-step using the forward scheduler to produce X1, X2, ..., XT.
During generation, it's not guaranteed that Xt will map back to Xt-1, so the method introduces a correction term z. This enables perfect reconstruction with the original prompt and meaningful edits with new prompts.
However, in few-step generation, directly using z leads to artifacts like ghosting and silhouette remnants, especially when the edit involves structural change. We identify the cause: the correction terms are spatially aligned with the original image, not the edited one.
Cora addresses this by aligning z to the target content using pixel correspondences computed from diffusion features, enabling clean, structure-consistent edits even in few-step settings.
Correspondence-aware Attention Interpolation
Attention Interpolation
Illustrating attention interpolation with varying α values.
We reuse self-attention keys and values from the input image (via inversion) during generation to help preserve appearance.
However, the editing prompt may change appearance or introduce new content not present in the original image.
Prior methods either fully swap or concatenate input and target attention features, often causing conflicts between preservation and new content.
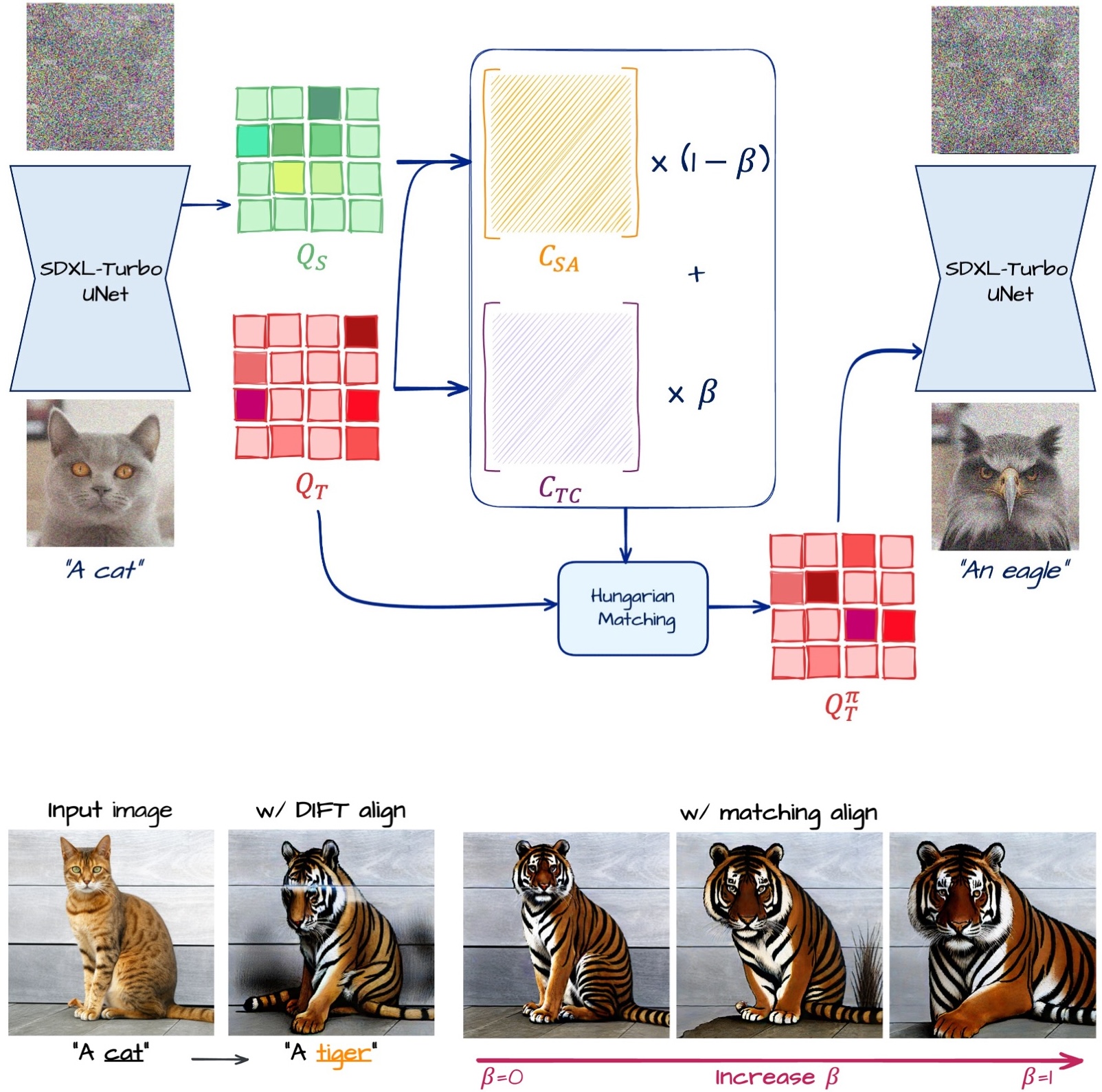
Instead, we align attention features using pixel-wise correspondences and apply interpolation between them.
This approach balances content preservation and flexibility, providing control over how much of the input's appearance is retained.
We found that using spherical linear interpolation (SLERP) yields better results compared to linear interpolation.
Content-adaptive Interpolation
Content-adaptive vs. non-adaptive interpolation across different image edits.
To generate new content, we identify image patches in the target that lack clear correspondence with the input.
We assign each patch a score based on how well it matches patches from the input image.
Patches with low correspondence scores are considered novel; we set their interpolation coefficient α = 1, allowing full guidance by the text prompt.
For other patches, α is set to a user-defined value to balance input preservation and new content generation.
Structure Alignment
To preserve the structure of the input image, we align self-attention queries of the target with those of the input.
Rather than direct pixel-wise alignment, we use one-to-one matching via the Hungarian algorithm, which effectively maintains structural consistency.
Visual Results
Comparison
Citation
@misc{almohammadi2025coracorrespondenceawareimageediting,
title={Cora: Correspondence-aware image editing using few step diffusion},
author={Amirhossein Alimohammadi and Aryan Mikaeili and Sauradip Nag and Negar Hassanpour and Andrea Tagliasacchi and Ali Mahdavi-Amiri},
year={2025},
eprint={2505.23907},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.23907},
}